概要
前の記事で、パンまつりについてコスパ良い商品はどれかという調査をしていました。前の記事はこちらから↓
コスパを調べるには対象商品とその商品に対する価格情報が必要になるので、どこから情報を得ようかなと考えていました。幸い対象商品については公式サイトが商品とそのポイントについて一覧を出していたため難なく得られました。が、商品価格はどこにも載っていない..。
そのときに、公式サイトにある対象商品一覧を使って商品価格についてネットスーパーに表示されている価格でスクレイピングしようとしたときの失敗談です。ちなみに、今回の対象商品は398商品もありましたので、手動でやるには手間だなと思ったのが背景です。
あくまで失敗談なのであしからず。
筆者はうぶの素人なので、もしかしたらスクレイピングというよりはちょっとした自動化に近いのかなと思ったり。うーむ、スクレイピングは奥が深い…。
プログラム
使用環境
まずは使用環境です。基本的にPythonを使って、SeleniumとBeautifulSoupを使用しました。以下がバージョン情報についてです。
- python == 3.10.14
- beautifulsoup == 4.14.3
- requests == 2.33.1
- selenium == 4.43.0
ちなみに、SeleniumはWebブラウザの操作をプログラム上で実装することのできるライブラリで、BeautifulsoupはHTMLやXMLのデータ構造解析のためのライブラリです。そちらを使えばやりたいことが実装できそうな気がしました。
さらに、Geminiさんにも手伝ってもらいました!毎度失礼します。
処理の流れ
基本的な処理の流れは簡単に、以下の感じにしました。ちょいプロなので、手間をかけないで実装したい…!
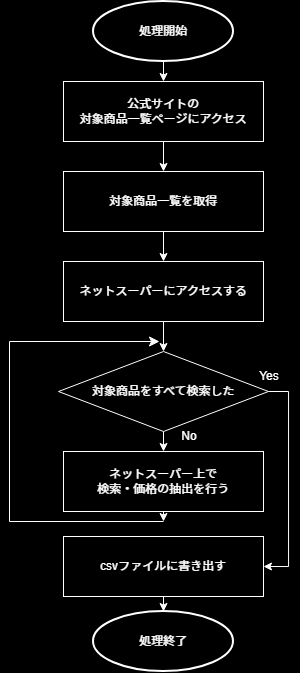
6ステップですね。
- 公式サイトの対象商品一覧ページにアクセス
- 対象商品一覧を取得
- ネットスーパーにアクセスする
- ネットスーパー上で検索・価格の抽出を行う (図と順番が入れ替わっていること注意⚠)
- 対象商品をすべて検索するまでループ(図と順番が入れ替わっていること注意⚠)
- 結果をcsvファイルに書き出す
1,2のステップでは静的ページを取得してそこで対象商品の一覧とポイントを取得してきます。その後、価格を抽出するために3,4ステップで、取得した情報をもとに検索をし、ループの5ステップを回していきます。そして得られた結果をcsvに書き出していくという流れです。
対象のネットスーパーは「Green Beans」さんにしました。
なんか上手くいきそう…!!
1, 2. サイトへのアクセス・対象商品一覧を取得する関数
最初に、対象商品一覧のあるHTML構造を確認します。
サイトにアクセスして、F12キーを押します。すると、右側にずらっとサイトの中身が映ります。ここから根気よく抜き出したい情報に共通するタグなど拾ってきます。私はこのやり方でしたが、もう少しいいやり方あれば知りたいところですね…。
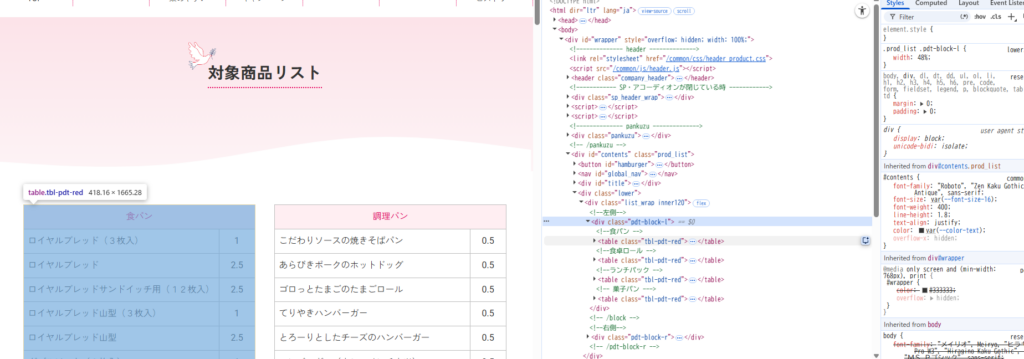
頑張ってIDやClassなどを抽出して”これだ”というものを検索するようにしたコードがこちらです。○〇.findで探してるなーと思ってください。そして、辞書型に一旦退避しています。
url="https://www.xxxxx.実際の対象商品一覧サイトURLを使用してください。"
driver = webdriver.Chrome()
response = requests.get(url)
soup = BeautifulSoup(response.text, 'html.parser')
### 対象製品一覧を取得
labels = soup.find_all('td', class_='cell_l')
values = soup.find_all('td', class_='cell_r')
data_dicts = []
for label, value in zip(labels, values):
key = label.get_text(strip=True)
val = value.get_text(strip=True)
data_dicts.append({'target':key, 'point':val})
3,4,5. 検索・価格の抽出を行う関数
上記と同じように、検索・価格を行うためのネットスーパーサイトについて構造を確認していきます。どうやら検索欄はIDがsearchで、検索をしても変わらないようなので、それを使おうと思います。IDがsearchな部品の値を変えていく動作で、入力したら虫眼鏡マークを押すという動作がよさそうですね。
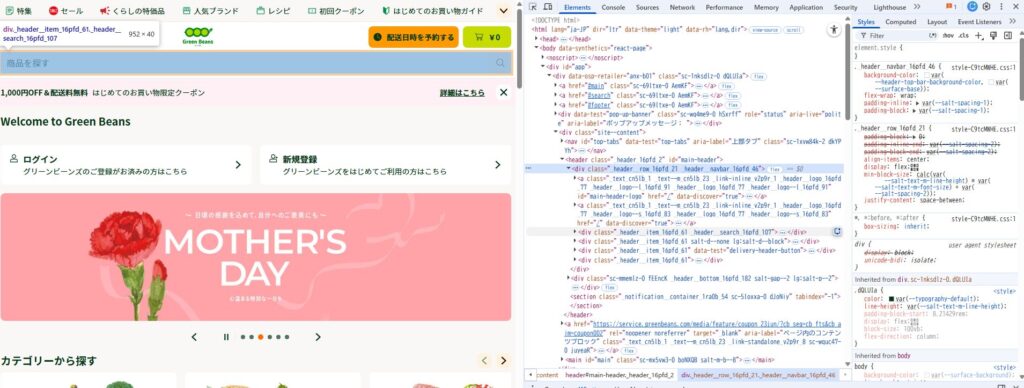
検索ボタンを押す操作のコードは以下の感じです。
def scrayping(driver, search_url, search_keyword):
# 1. ウェブページにアクセス
driver.get(search_url)
# 2. 検索入力欄(id="search")が見つかるまで最大5秒待機
wait = WebDriverWait(driver, 5)
search_input = wait.until(EC.presence_of_element_located((By.ID, "search")))
# 3. 値を入力
search_input.clear() # 念のため既存の入力をクリア
search_input.send_keys(search_keyword)
# 4. ヘッダー内にあるボタンを探してクリック
header = driver.find_element(By.TAG_NAME, "header")
submit_button = wait.until(EC.element_to_be_clickable(
(By.CSS_SELECTOR, "header button[type='submit']")
))
submit_button.click()
# 5. 検索結果が表示されるまで待機(例:title_containerが出るまで)
wait.until(EC.presence_of_element_located((By.ID, "main")))次に、価格の抽出を行うのは以下のコードです。ネストが深くて見づらいですね。どれが不変のタグなのか難しかったです。
def search(target, target_labels, new_html_content):
# 別のページの解析
soup_new = BeautifulSoup(new_html_content, 'html.parser')
items = soup_new.find_all(class_="product-card-container") # 仮の親クラス名
results = []
for item in items:
# 1. title_container 配下の <a> 配下の <h3> を取得
title_container = item.find(class_="title-container")
if not title_container:
continue
h3_tag = title_container.find('a').find('h3') if title_container.find('a') else None
if h3_tag:
h3_text = h3_tag.get_text(strip=True)
# 2. cell_lの値と合致するか判定
matched_label = next((label for label in target_labels if label in h3_text), None)
if matched_label:
# 3. 同じ親要素内にある footer-container を探す
footer = item.find(class_="footer-container")
if footer:
# 4. data-test="fop-price" を取得
price_tag = footer.find(attrs={"data-test": "fop-price"})
if price_tag:
price = price_tag.get_text(strip=True)
results.append({"item":target, "label": h3_text, "price": price})
if len(results) == 0: return None
else: return resultsメイン関数
最後に、全体を制御するメイン関数を載せておきます。
反省点が二つくらい…。
- 辞書型を使ったのですが、値を持ってくるときにハードコーディングしてしまって保守性がなさすぎるコードになってしまいました。
- 最後のcsvも間に合わせでfieldnameをくっつけました
def main():
url="https://www.xxxxx.実際の対象商品一覧サイトURLを使用してください。"
search_url = "https://実際のネットスーパーサイトURLを使用してください。"
driver = webdriver.Chrome()
output_csv = "./data.csv"
response = requests.get(url)
soup = BeautifulSoup(response.text, 'html.parser')
### 対象製品一覧を取得
labels = soup.find_all('td', class_='cell_l')
values = soup.find_all('td', class_='cell_r')
data_dicts = []
for label, value in zip(labels, values):
key = label.get_text(strip=True)
val = value.get_text(strip=True)
data_dicts.append({'target':key, 'point':val})
###
output_list = []
target_labels = [item["target"] for item in data_dicts]
try:
for data in data_dicts:
target = data["target"]
scrayping(driver, search_url, target)
result = search(target, target_labels, driver.page_source)
if result != None:
output_list.append(result)
with open(output_csv, 'w', encoding='utf_8_sig', newline='') as csvfile:
fieldnames = ['item', 'label', 'price']
writer = csv.DictWriter(csvfile, fieldnames=fieldnames)
writer.writeheader()
# 外側のリストをループ
for sublist in output_list:
# 内側のリストにある辞書を一つずつ取り出す
for row in sublist:
writer.writerow(row)
finally:
pass動作確認
実際に動かしてみると以下の画像みたいになります。画像左に、Webブラウザが開かれて検索してくれてます。
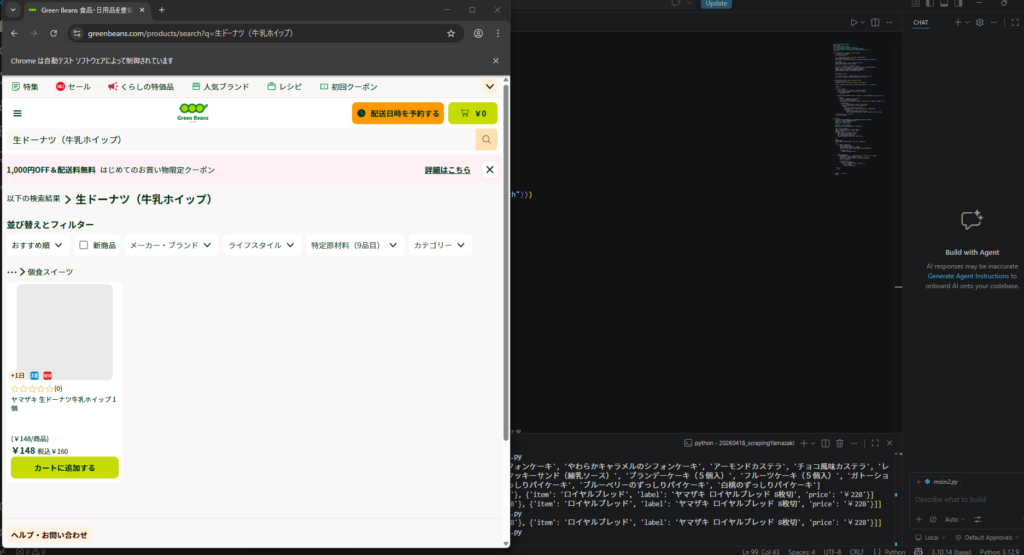
なんか上手く動いてそう…!
そして、最後に出力されたcsvをのぞいてみると…

少ない…!!
というか画像の「生ドーナツ」の検索結果はどこ行った…!?証拠は残っているんだけど!?
ということで、あんまり上手くいかなかったです。自作関数のsearch関数の条件が厳しかったのかなぁと思ったり…。ポイントを含めるのを忘れていた…!ということも気づきました。
もう少し再考の余地がありそうですが、これなら社名で絞って商品名と価格を取得してきたほうが速いのではと思い、そっちにシフトしました。
まとめ
パンの価格の取得取得を目的に、一覧の取得からネットスーパーでの検索を自動化するチャレンジをしてみました。結果は見ての通り惨敗…。
前回記事の価格抽出ではこれをすべて使うのではなく、会社名で絞って出た画面から、商品名と価格を抽出しました。このようなスクレイピングをやることは初めてだったのですが、コードを書く前の方針が大事だなと改めて思いました。
でも、始めてやることは学びが多くて楽しいですね。また、何かの機会にやってみようと思います。
ここまで読んでいただきありがとうございました。また次回の記事で。
コメントを残す